개요

도서 인사이트 공유 프로젝트 `지성인`에는 베스트셀러 도서를 매일 최신화하는 로직이 존재한다.
매일 오전 4시에 베스트셀러 상위 100권 정보를 크롤링하여 서버에 저장한다.
처음에는 동기 방식의 HTTP 작업으로 수행하여 시간이 오래걸리는 비효율적인 문제가 발생했다.
그래서 이 문제를 해결하기 위해 CompletableFuture를 활용한 비동기 처리와 병렬 프로그래밍으로 개선을 시도했다.
이 글에서는 기존 동기적인 접근 방식에서 겪었던 지연 문제를 어떻게 해결했는지, 그리고 새로운 방법으로 얼마나 개선됐는지 공유해본다.
문제 상황
@Component
@RequiredArgsConstructor
public class Yes24Crawler implements Crawler {
private final Fetcher fetcher;
private final Parser parser;
@Override
public Map<Long, CrawledBook> crawlBestSellers() {
Map<Long, String> bestSellerIds = parser.
parseBestSellerIds(fetcher.fetchBestSellerIds());
return bestSellerIds.entrySet()
.stream()
.collect(Collectors.toMap(
Map.Entry::getKey,
entry ->
parser.parseBook(fetcher.fetchBook(entry.getValue()))
));
}
}
해당 코드는 parser.parseBestSellerIds(...) 메서드로 100권의 도서 id를 가져와서, 다시 상세 도서 정보를 크롤링하여 순위 정보와 함께 Map으로 매핑하여 리턴해준다.
애초에 베스트셀러 페이지에 도서 상세 정보가 제공되지 않아서, 베스트셀러 도서 id를 먼저 가져와서 상세정보를 또 크롤링하는 로직으로 구현할 수 밖에 없었다.
아래는 위 코드의 수행시간이다.

왜 ?
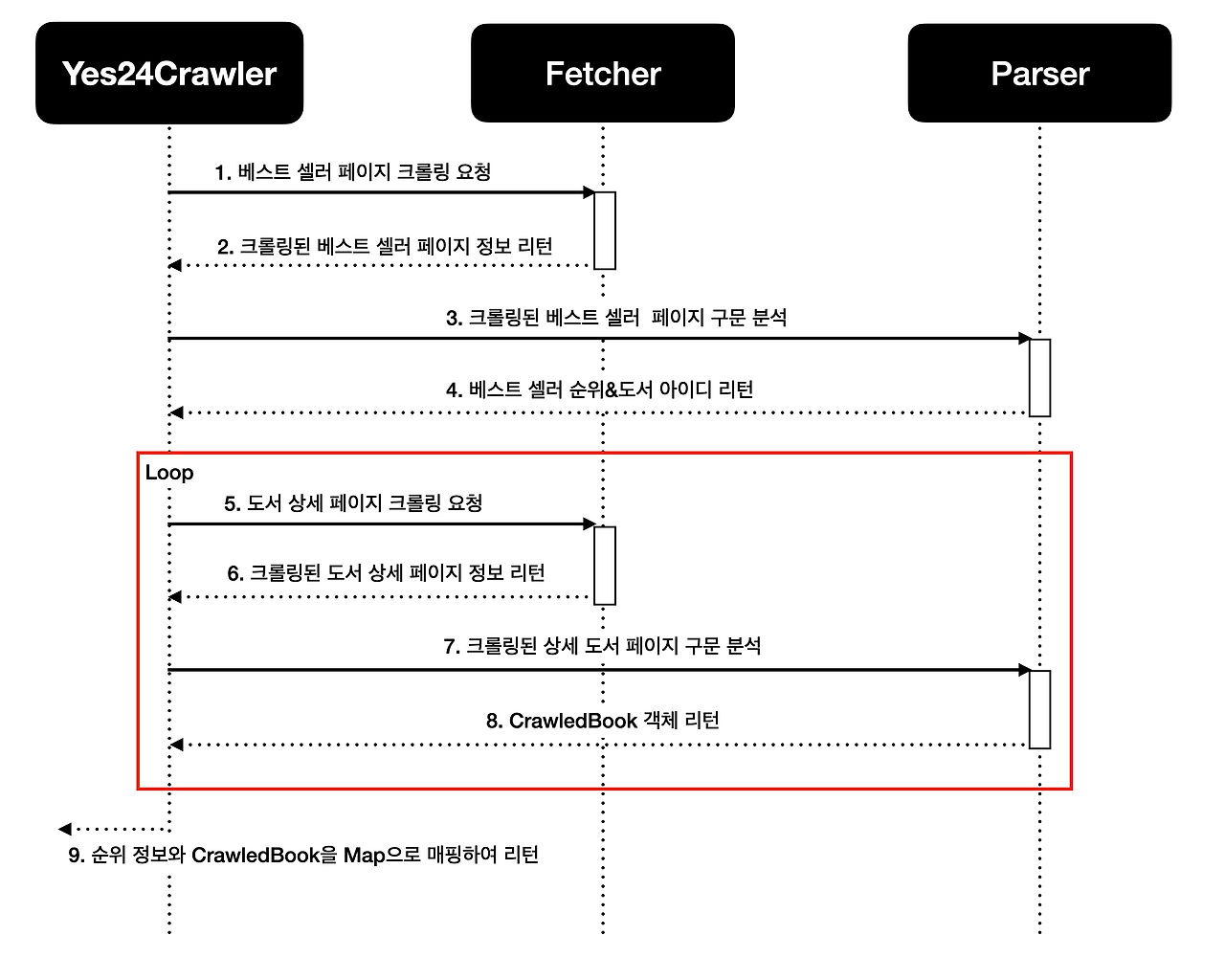
현재 코드에서의 문제점은 모든 도서에 대한 HTTP 요청이 순차적으로 처리되어서 크롤링 시간이 비효율적으로 소요된다.

첫 번째 도서의 정보를 가져온 후, 두 번째 도서의 정보를 가져오는 방식으로 처리되고 있어서 전체적인 처리 시간이 크게 증가한다.
이런 문제를 해결하기 위해 병렬 처리를 도입하여 HTTP 요청을 동시에 수행하는 방법을 적용해야 한다.
이를 통해 각 도서의 정보를 독립적으로 가져오면서 처리 시간을 크게 줄일 수 있다.
해결 방법
CompletableFuture
CompletableFuture는 기존의 Future 인터페이스가 제공하지 못했던 비동기 결과 값의 조합과 예외 처리를 갖추고 있어서 효율적으로 기능을 수행하도록 기능을 제공한다.
덕분에 동기 코드를 비동기 코드로 변환하여 성능을 개선하고, 더 유연한 비동기 처리 로직을 구현할 수 있다.
코드로 살펴보자.
@Component
@RequiredArgsConstructor
public class Yes24Crawler implements Crawler {
private final Fetcher fetcher;
private final Parser parser;
@Override
public Map<Long, CrawledBook> crawlBestSellers() {
Map<Long, String> bestSellerIds = parser.parseBestSellerIds(fetcher.fetchBestSellerIds());
Map<Long, CrawledBook> crawledBookMap = new ConcurrentHashMap<>();
List<CompletableFuture<Void>> futures = bestSellerIds.entrySet().stream()
.map(entry -> CompletableFuture.supplyAsync(() -> parser.parseBook(fetcher.fetchBook(entry.getValue())))
.thenAccept(crawledBook -> crawledBookMap.put(entry.getKey(), crawledBook))
.toList();
CompletableFuture.allOf(futures.toArray(CompletableFuture[]::new)).join();
return crawledBookMap;
}
}베스트셀러 ID 파싱
Map<Long, String> bestSellerIds = parser.parseBestSellerIds(fetcher.fetchBestSellerIds());
베스트 셀러 ID를 파싱하여 Map<Long, String>에 할당한다.
해당 로직은 동기적으로 수행한다.
비동기 데이터 처리
bestSellerIds.entrySet().stream()
.map(entry -> CompletableFuture.supplyAsync(() -> parser.parseBook(fetcher.fetchBook(entry.getValue()))))
.thenAccept(crawledBook -> crawledBookMap.put(entry.getKey(), crawledBook))
.toList();
bestSellerIds의 각 항목에 대해 CompletableFuture.supplyAsync(...)를 사용하여 비동기 작업을 시작한다.
이 작업은 fetcher.fetchBook(...)을 통해 크롤링한 상세 도서 정보를 parser.parseBook(...)을 통해 책 정보를 파싱한다.
그 후 각 비동기 작업이 완료되면 thenAccept(...)를 통해 crawledBookMap에 결과를 저장한다.
비동기 작업 대기
CompletableFuture.allOf(futures.toArray(CompletableFuture[]::new)).join();
CompletableFuture.allOf(...)는 모든 비동기 작업이 완료될 때까지 기다리는 새로운 CompletableFuture를 반환한다.
CompletableFuture가 블로킹 되는 것 같지만, CompletableFuture가 실제로 완료될 때까지 블로킹하지 않는다.
따라서 join()을 호출하여 CompletableFuture.allOf()가 반환한 CompletableFuture의 완료를 기다려야 모든 비동기 작업이 완료된 상태를 보장할 수 있다.
그렇지 않으면 비동기 작업이 완료되기 전에 메인 스레드가 종료되어 결과를 제대로 얻지 못할 수 있다.
결과


위와 같이 개선된 상황에서 수행 시간은 3.510sec이 걸렸다.
결과적으로 약 1006%의 성능 개선이 되었음을 확인할 수 있다. 😚
작업 PR
https://github.com/jisung-in/backend/pull/42
[Feature] 베스트 셀러 크롤링 기능 추가 by jwooo · Pull Request #42 · jisung-in/backend
💡 연관된 이슈 close #34 📝 작업 내용 베스트 셀러 BookId 크롤링 기능 BookId를 통한 도서 상세 정보 크롤링 기능 💬 리뷰 요구 사항 베스트 셀러 목록을 가져와서 처리하는 부분을 CompletableFuture를
github.com
'2024' 카테고리의 다른 글
| RTR 방식과 Refresh Token을 Redis에 저장하는 이유 (0) | 2024.10.14 |
|---|---|
| RESTful한 path 설계하기 (0) | 2024.10.05 |
| Spring MSA 환경 배포 자동화에 대한 인프라 아키텍처 고민 (0) | 2024.09.07 |
| 24년 상반기 회고 (0) | 2024.08.14 |
| AOP를 통한 유저 인증 정보 미리 주입하기 (0) | 2024.07.23 |