1. 전문 검색 인덱스
B-Tree 인덱스 같은 경우는 전체 일치나 좌측 일부 일치와 같은 검색만 가능하다.
전문 검색 인덱스는 문서 전체를 인덱스화해서 특정 키워드가 포함된 내용을 검색할 수 있다.
사용자에게 빠른 검색을 제공하기 위해 키워드로 인덱스를 구축한다.
1-1. 어근 분석 알고리즘
불용어 처리 : 별 가치가 없는 단어를 모두 필터링해서 제거하는 작업
불용어는 개수 자체가 많지 않아서 상수로 정의해서 사용한다.
사용자가 불용어를 직접 설정해서 적용할 수 있다.
어근 분석 : 검색어로 선정된 단어의 뿌리인 원형을 찾는 작업
형태소 분석 프로그램 MeCab이나 MongoDB에서 사용되는 Snowball이라는 오픈소스로 어근 분석을 한다.
MeCab 같은 경우는 일본어 전용이기 때문에 한글에 맞게 완성도를 갖추는 작업은 오래 걸린다.
1-2. n-gram 알고리즘
MeCab의 단점을 보완하기 위해 n-gram 알고리즘이 도입되었다.
형태소 분석이 문장을 이해하는 알고리즘이라면, n-gram은 단순한 키워드를 검색해 내기 위한 인덱싱 알고리즘이다.
n-gram은 n글자씩 잘라서 인덱싱 하기 때문에 인덱스의 크기는 큰 편이다.
보통 2글자 단위로 인덱싱하는 2-gram이 많이 쓰인다.
아래 예제로 살펴보자.
To be or not to be. That is the question
다음과 같은 문장이 주어지면 공백과 마침표를 기준으로 2 글자씩 10개의 토큰이 생성된다.
생성된 토큰에 대해서 불용어와 동일하거나 불용어를 포함하는 경우 걸러서 버린다.
살아남은 토큰만 전문 검색 인덱스에 등록한다.
1-3. 전문 검색 인덱스의 가용성
- 쿼리 문장이 전문 검색을 위한 문법 사용 (MATCH ... AGAINST ...)을 사용해야 한다.
- 테이블이 전문 검색 대상 칼럼에 대해서 전문 인덱스를 보유해야 한다.
CREATE TABLE tb_test (
doc_id INT,
doc_body TEXT,
PRIMARY KEY (doc_id),
FULLTEXT KEY fx_docbody (doc_body) WITH PARSER ngram
) ENGINE = InnoDB;
-- 풀 테이블 스캔
SELECT * FROM tb_test WHERE doc_body LIKE `%애플%`;
-- 전문 검색 인덱스
SELECT * FROM tb_test WHERE MATCH(doc_body) AGAINST(`애플` IN BOOLEAN MODE);전문 검색 인덱스를 사용하려면 테이블을 생성할 때 전문 인덱스를 생성한다.
그리고 두 번째 조회 문장처럼 (MATCH ... AGAINST ...) 문법을 사용한다.
2. 클러스터링 인덱스
전문 검색 인덱스를 제외한 모든 인덱스는 레코드 1건이 1개의 인덱스 키 값을 가진다.
멀티 밸류 인덱스는 하나의 레코드가 여러 개의 키 값을 가질 수 있다.
정규화에 위배되는 행위지만, JSON 배열 타입을 저장하기 위해 사용된다.
CREATE TABLE user (
user_id BIGINT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(10),
last_name VARCHAR(10),
credit_info JSON,
INDEX mx_creditscores( (CAST(credit_info->'$.credit_scores' AS UNSIGNED ARRAY)) )
INSERT INTO user VALUES(1, 'Matt', 'Lee', '{"credit_scores":[360, 353, 351]}');
SELECT * FROM user WHERE 360 MEMBER OF(credit_info -> '$.credit_scores');다음과 같이 JSON 타입을 조회할 수 있다.
MEMBER OF(), JSON_CONTAINS(), JSON_OVERLAPS() 등과 같은 함수를 사용해서 검색할 수 있다.
클러스터링 인덱스는 비슷한 것들끼리 묶어서 저장하는 형태로 구현된다.
주로 비슷한 값들을 동시에 조회하는 경우가 많기 때문이다.
클러스터링 인덱스는 테이블의 프라이머리 키에 대해서만 적용된다.
중요한 것은 프라이머리 키 값에 따라 레코드의 저장 위치가 결정된다.
프라이머리 키 값이 변경된다면 레코드의 물리적인 저장 위치도 변경된다는 것을 의미한다.
프라이머리 키에 대한 의존도가 상당히 크기 때문에 프라이머리 키를 신중히 결정해야 한다.
클러스터링 인덱스로 저장되는 테이블은 프라이머리 키 기반의 검색이 상당히 빠르다.
대신 레코드의 저장이나 프라이머리 키의 변경이 상대적으로 느리다.
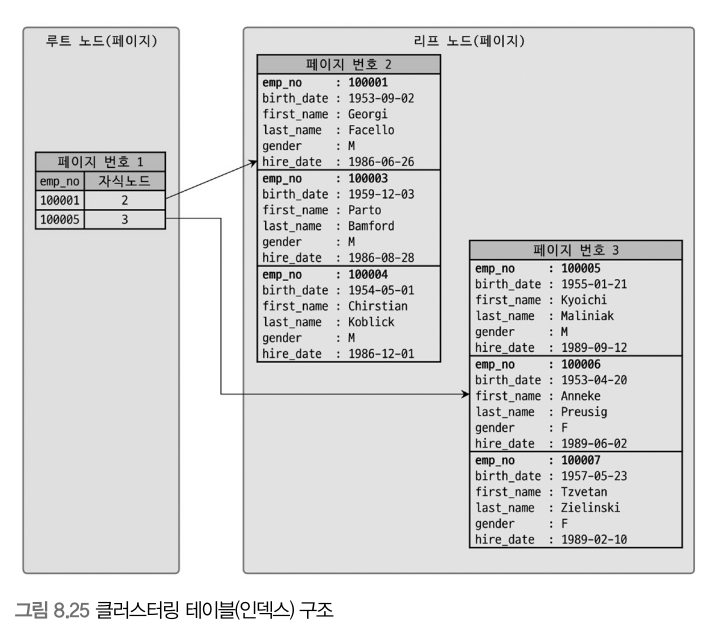
클러스터링 인덱스 구조를 보면 클러스터링 테이블 구조 자체는 B-Tree와 비슷하다.
차이는 리프 노드에 캐시 데이터 페이지가 존재한다.
그러면 프라이머리 키가 없는 경우, 클러스터링 테이블은 어떻게 구성될까 ?
- 프라이머리 키가 있으면 기본적으로 프라이머리 키를 클러스터링 키로 선택
- NOT NULL 옵션의 유니크 인덱스 중에서 첫 번째 인덱스를 클러스터링 키로 선택
- 자동으로 유니크한 값을 가지도록 증가하는 칼럼을 내부적으로 추가한 후, 클러스터링 키로 선택
2-1. 세컨더리 인덱스에 미치는 영향
인덱스가 실제 레코드가 저장된 주소를 가지고 있다면 어떻게 될까 ?
클러스터링 키 값이 변경될 때마다 데이터 레코드의 주소도 바뀐다.
그때마다 테이블의 모든 인덱스의 저장된 레코드 주소 값을 변경해야 한다.
이런 오버헤드를 제거하기 위해 InnoDB 테이블에서 모든 세컨더리 인덱스는 프라이머리 키 값을 저장한다.
CREATE TABLE employees (
emp_no INT NOT NULL;
first_name VARCHAR(20) NOT NULL,
PRIMARY KEY (emp_no),
INDEX ix_firstname (first_name)
);
SELECT * FROM employees WHERE first_name='Aamer';MyISAM : ix_firstname 인덱스를 검색해서 레코드의 주소를 확인한 후, 레코드 주소로 최종 레코드를 가져온다.
InnoDB : ix_firstname 인덱스를 검색해서 레코드의 PK를 확인한 후, PK 인덱스를 검색해서 최종 레코드를 가져온다.
2-2. 클러스터링 인덱스의 장점과 단점
장점
- PK 키로 검색할 때 처리 성능이 매우 빠르다.
- 테이블의 모든 세컨더리 인덱스가 PK를 가지고 있기 때문에 인덱스만으로 처리될 수 있다. (커버링 인덱스)
단점
- 모든 세컨더리 인덱스가 클러스터링 키를 갖기 때문에 전체적으로 인덱스 크기가 커진다.
- 세컨더리 인덱스로 검색할 때 프라이머리 키로 다시 한 번 검색해야 한다.
- INSERT 할 때 프라이머리 키에 의해 레코드 저장 위치가 결정되기 때문에 처리 성능이 느리다.
- 변경할 때 레코드를 DELETE 하고 INSERT 하는 작업이 필요하기 때문에 처리 성능이 느리다.
온라인 트랜잭션 환경에서는 읽기 비율이 쓰기 비율보다 훨씬 높기 때문에 읽기를 빠르게 유지하는 것이 중요하다.
2-3. 클러스터링 테이블 주의사항
- 세컨더리 인덱스는 클러스터링 키를 포함하기 때문에 PK가 커지면 세컨더리 인덱스도 커진다.
그래서 PK를 신중하게 선택해야 한다. - 가능한 경우 PK는 AUTO-INCREMENT보다는 업무적인 칼럼으로 설정한다.
PK가 중요한 역할을 하기 때문에 해당 레코드를 대표할 수 있다면 그 칼럼을 PK로 설정한다. - 적어도 AUTO-INCREMENT로 PK를 생성하는 것이 좋다.
PK를 설정하지 않아도 일련번호 칼럼이 생성되기 때문에 사용자가 접근할 수 있도록 미리 생성하자. - 칼럼이 복합으로 만들어진 PK의 경우 크기가 커지는 경우가 있다.
PK를 대체하기 위해 AUTO-INCREMENT를 이용한 인조 식별자를 생성하자.
3. 유니크 인덱스
유니크는 인덱스보다는 제약 조건의 가깝다.
유니크 인덱스
테이블이나 인덱스에 같은 값이 2개 이상 저장될 수 없다. ( 인덱스 없이 유니크 제약만 걸 수 없음 )
NULL은 특정 값이 아니므로 2개 이상 저장될 수 있다.
PK : NULL이 허용되지 않는 유니크 인덱스 + 클러스터링 키의 역할
3-1. 유니크 인덱스와 세컨더리 인덱스
인덱스 읽기
유니크하지 않은 세컨더리 인덱스는 레코드를 한 건 더 읽어야 하므로 느리다고 생각한다.
하지만 이 작업은 디스크 읽기가 아니라 CPU에서 칼럼을 비교하는 작업이기 때문에 성능에 영향이 거의 없다.
그저 인덱스의 성격이 다를 뿐이고, 1개의 레코드를 읽느냐 2개 이상의 레코드를 읽느냐의 차이만 있다.
인덱스 쓰기
새로운 레코드가 INSERT 되거나 인덱스 칼럼의 값이 변경된 경우, 인덱스 쓰기 작업이 필요하다.
유니크 인덱스의 쓰기 작업은 중복된 값이 존재하는지 체크하는 과정이 필요하다.
중복된 값을 체크할 때는 읽기 잠금을 사용하고, 쓸 때는 쓰기 잠금을 사용하는데 이 과정에서 데드락이 발생한다.
InnoDB에서는 인덱스 키의 저장을 버퍼링 하기 위해 체인지 버퍼가 사용된다.
그래서 인덱스 저장, 변경 작업이 빠르게 처리되지만 유니크 인덱스는 중복 체크 때문에 버퍼링 하지 못한다.
결론적으로 유니크 인덱스는 세컨더리 인덱스보다 변경 작업이 더 느리게 동작한다.
3-2. 유니크 인덱스 주의 사항
CREATE TABLE tb_unique (
id INTEGER NOT NULL,
nick_name VARCHAR(100),
PRIMARY KEY (id),
UNIQUE INDEX ux_nickname (nick_name),
INDEX ix_nickname (nick_name) -- 중복된 일반 인덱스
);MySQL의 유니크 인덱스는 일반 인덱스와 같은 역할을 하므로 중복해서 인덱스를 생성하지 않아도 된다.
그리고 똑같은 칼럼에 대해 PK와 유니크 인덱스를 동일하게 생성한 경우도 불필요한 중복이므로 주의하자.
유일성이 보장되는 칼럼에 대해서는 유니크 인덱스를 생성하되, 필요하지 않다면 세컨더리 인덱스를 고려하자.
4. 외래키
MySQL에서 외래키는 InnoDB 스토리지 엔진에서만 생성할 수 있다.
외래키 제약이 설정되면 자동으로 연관되는 테이블 칼럼의 인덱스까지 생성된다.
- 테이블의 변경(쓰기 잠금)이 발생하는 경우에만 잠금 경합이 발생한다.
- 외래키와 연관되지 않은 칼럼의 변경은 최대한 잠금 경합을 발생시키지 않는다.
CREATE TABLE tb_parent (
id INT NOT NULL,
fd VARCHAR(100) NOT NULL, PRIMARY KEY (id)
) ENGINE = InnoDB;
CREATE TABLE tb_child (
id INT NOT NULL,
pid INT DEFAULT NULL, -- parent.id 칼럼 참조
fd VARCHAR(100) DEFAULT NULL,
PRIMARY KEY (id),
KEY ix_parendid (pid),
CONSTRAINT child_ibfk_1 FOREIGN KEY (pid) REFERENCES tb_parent (id) ON DELETE CASCADE
) ENGINE = InnoDB;
INSERT INTO tb_parent VALUES (1, 'parent-1'), (2, 'parent-2');
INSERT INTO tb_child VALUES (100, 1, 'child-100');자식 테이블의 변경이 대기하는 경우
1번 커넥션에서 부모 테이블의 id가 2인 레코드를 변경하면 id가 2인 레코드에 대해 쓰기 잠금을 획득한다.
자식 테이블의 외래키 칼럼을 2로 변경하는 작업은 부모 테이블의 변경 작업을 기다린다.
1번 커넥션의 작업이 ROLLBACK이나 COMMIT 되면 2번 커넥션의 대기 중이던 작업이 즉시 완료된다.
이는 첫 번째 특징에 해당한다.
자식 테이블의 외래키가 아닌 칼럼의 변경은 잠금 확장이 발생하지 않는다.
이는 두 번째 특징에 해당한다.
부모 테이블의 변경이 대기하는 경우
1번 커넥션에서 부모 키 1을 참조하는 자식 테이블의 레코드를 변경하면 쓰기 잠금을 획득한다.
2번 커넥션이 부모 테이블에서 id가 1인 레코드를 삭제하는 경우, 쓰기 잠금 해제를 기다린다.
ON DELETE CASCADE 때문에 부모 레코드가 삭제되면 자식 레코드도 동시에 삭제되기 때문이다.
데이터베이스 외래키를 생성하려면 잠금 경합까지 고려해서 모델링하는 것이 중요하다.
자식 테이블에 레코드가 추가되는 경우 부모 테이블의 참조키를 체크하는 것도 중요하다.
하지만 이러한 체크 작업을 위해 연관 테이블에 읽기 잠금을 걸어야 한다는 사실을 기억하자.
이렇게 잠금이 확장되면 쿼리의 동시 처리 성능에 영향을 미친다.
'2024' 카테고리의 다른 글
| QueryDSL 동적 정렬 쿼리 OrderSpecifier 구현하기 (0) | 2024.03.28 |
|---|---|
| Spring Security 없이 소셜 로그인 구현하기 (0) | 2024.03.17 |
| [MySQL] Order By, Group By, Distinct (2) | 2024.01.30 |
| [MySQL] 인덱스와 B-Tree (1) | 2024.01.21 |
| [MySQL] 트랜잭션, 잠금, 격리 수준이 뭘까 ? (1) | 2024.01.08 |